摘要
Perplexity是AI+搜索引擎的创新者和领先者,卡位LLM+搜索引擎新业态。Perplexity于2022年8月成立,公司创始人曾任职于OpenAI,公司获OpenAI、Meta内部AI负责人等注资。Perplexity基于微调模型等通用智能生成能力及微软Bing搜索引擎构建,对比ChatGPT等生成式AI时效性更强、具备可溯源属性,对比谷歌等传统搜索引擎答案凝练、可实现上下文响应。我们认为,Perplexity依托于LLM+搜索的产品力、工程化能力、快速迭代能力在ToC应用中突围。
检索增强生成为核心技术,召回能力与响应速度树立差异化。检索增强生成技术(RAG)包含检索、生成两个环节。RAG融合外部知识库与模型先验知识,外部知识库丰富且易于更新的数据有效弥补了大模型数据滞后、伴有幻觉的劣势。Perplexity以RAG为基,在算法侧对检索系统的核心“召回”环节进行创新,召回率和精确度在同类产品中排名第一;在响应速度方面,Perplexity采用自研推理堆栈pplx-api,并在推理端使用TensorRT-LLM加速,延迟大幅降低;模型侧,公司对进行微调,在降低成本的同时进一步提升响应速度。
展望未来,我们认为对话式搜索引擎新业态有望成长为主流生态,但竞争趋于多元化,场景和数据闭环为核心要素。需求侧,Perplexity快速增长的用户数量验证了对话式搜索引擎的刚性需求,LLM+搜索的产品形态或将长期存在。供给侧,Perplexity产品定位对标NewBing、Bard,谷歌等互联网巨头具备数据和场景卡位优势,更易于实现AIAgent的场景闭环,竞争格局趋于多元化。但随着Perplexity社群、pplx-api生态的逐步完善,我们认为独立第三方的开放生态也有望助力公司夯实自身壁垒。
风险
商业化风险;数据闭环风险;行业竞争加剧风险。
正文
AI+搜索引擎,重塑知识发现新范式
Perplexity:AI对话式搜索引擎
图表1:Perplexity用户搜索界面及回答

图表2:ChatGPT回答界面

图表3:谷歌Bard回答界面
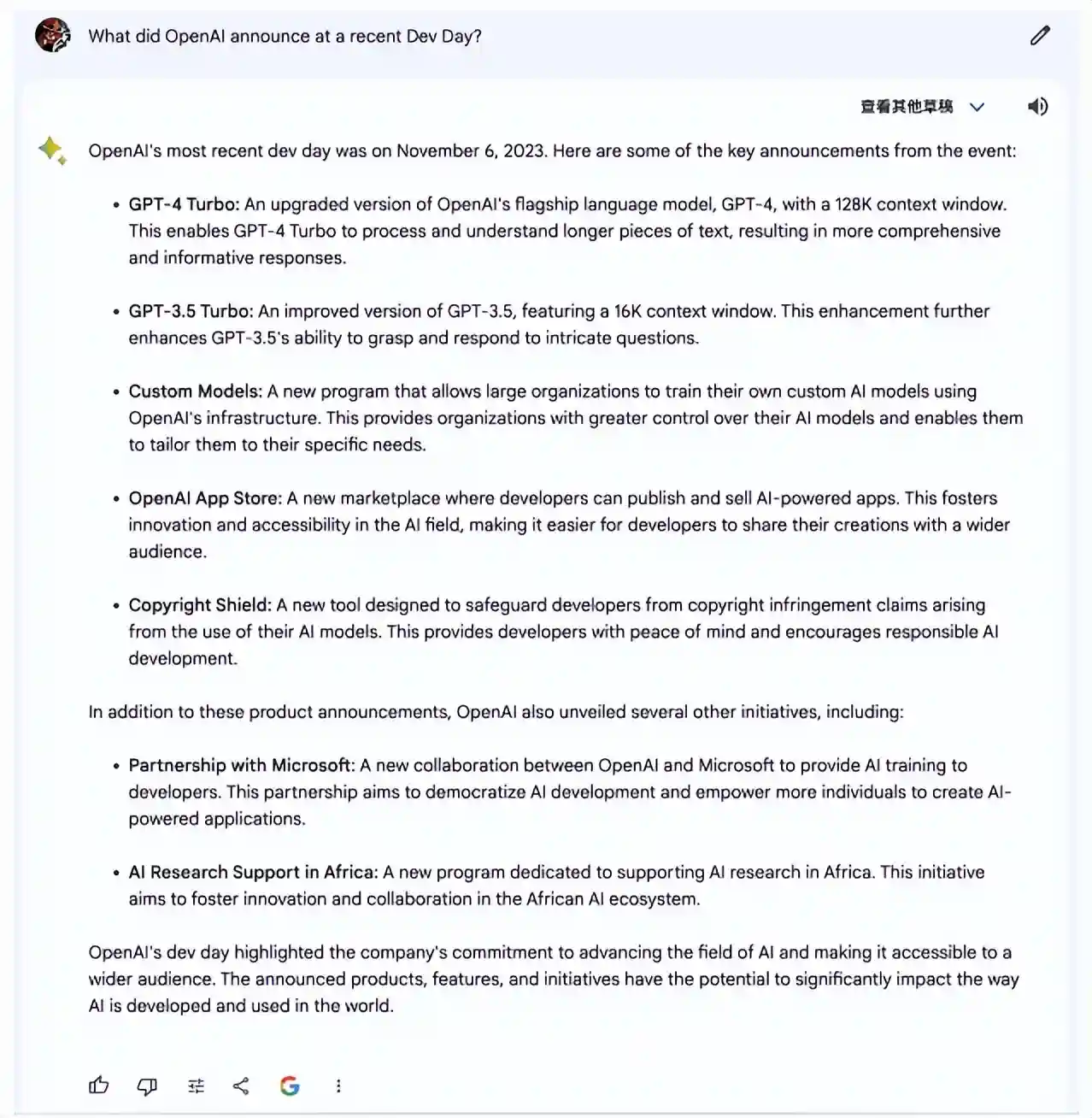
图表4:NewBing回答界面
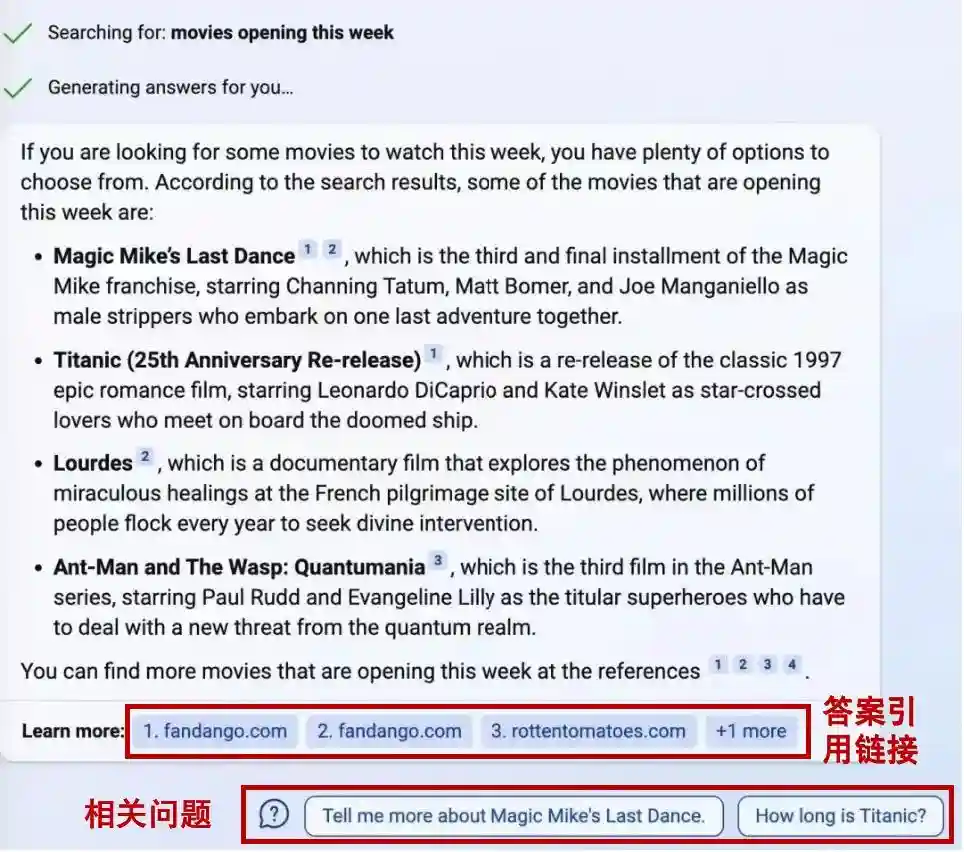
图表5:Perplexity支持多个垂类领域搜索
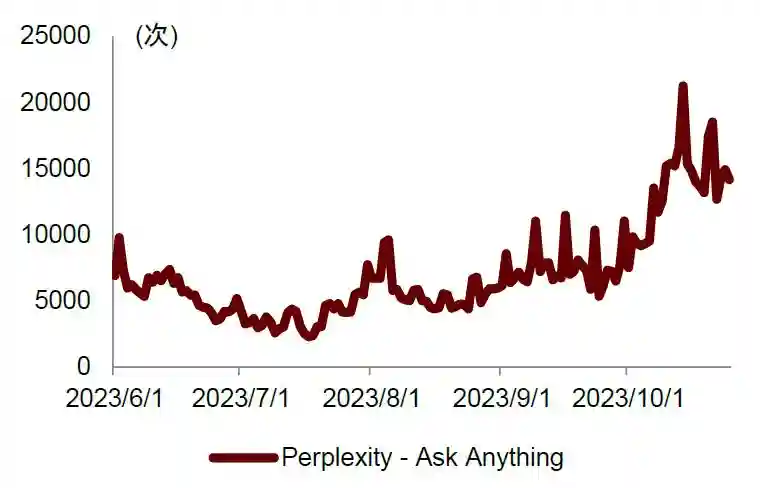
周度访问量环比高增,用户基础持续扩张彰显高粘性和成长性。Perplexity成立于2022年8月,致力于开发基于AI能力的对话式搜索引擎,以优化用户发现和共享知识的方式。2022年12月公司正式发布首个对话式搜索引擎Ask,此后其用户规模不断扩大,在四个月内月活跃用户数达到200万。根据SimilarWeb数据,截至2023年10月25日,PerplexityAPP的日度下载量为14,163次;2023年2月1日至10月25日,Perplexity网页端的周度访问量由275万增加至1,113万,增长3x;与同类别的AI搜索应用YouChat相比增长势头强劲。
图表6:PerplexityAPP下载量(日度)
注:数据截至2023年10月25日
图表7:海外搜索网页端AI应用访问量(周度)
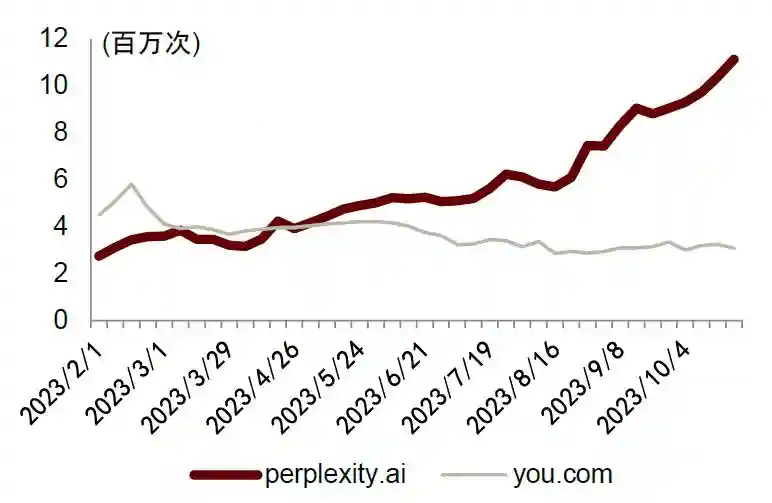
注:数据截至2023年10月25日
公司定位:LLM+搜索引擎的新业态,生成与检索兼容并包
Perplexity在ChatGPT与传统搜索引擎的基础上开发,兼具大模型的生成与推理能力,又囊括传统搜索引擎中内容的广度和时效性,是AI能力与搜索引擎的融合,定位与NewBing和Bard类似。搜索引擎具备搜索的实时性,但信息颗粒度以网页来衡量,未能实现搜索目的的“最后一公里”;而ChatGPT以生成式LLM为基础,实现了信息粒度的细化和融合,但实时性与幻觉[1]问题随之而来。Perplexity定位于LLM+搜索引擎的中间态,将二者优点相结合,侧重搜索体验的产品力而非基模型。
图表8:Perplexity与ChatGPT、传统搜索引擎差异化定位
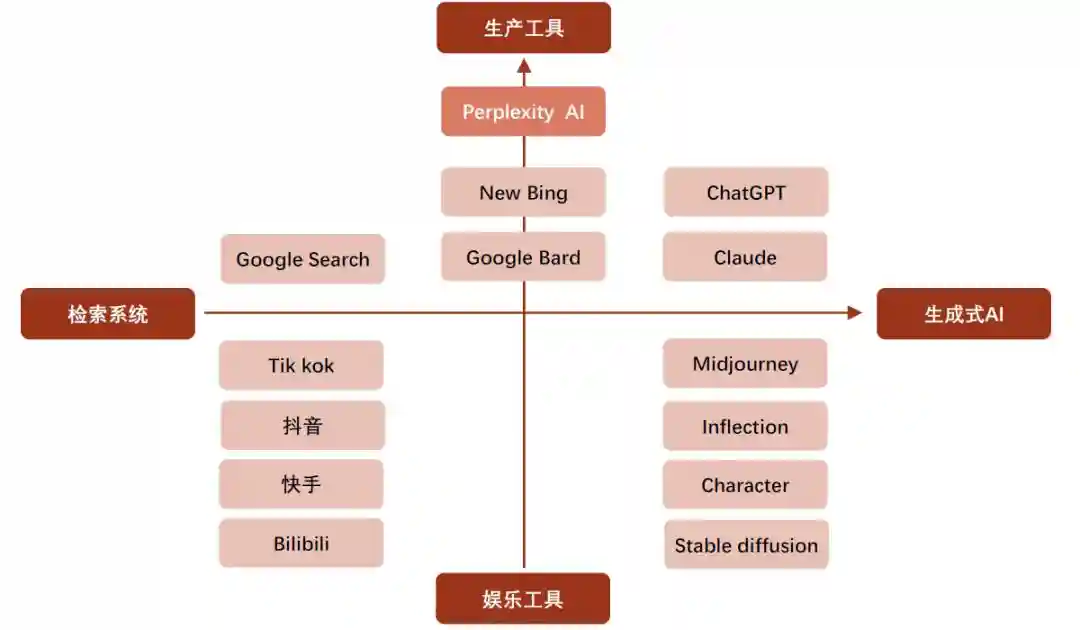
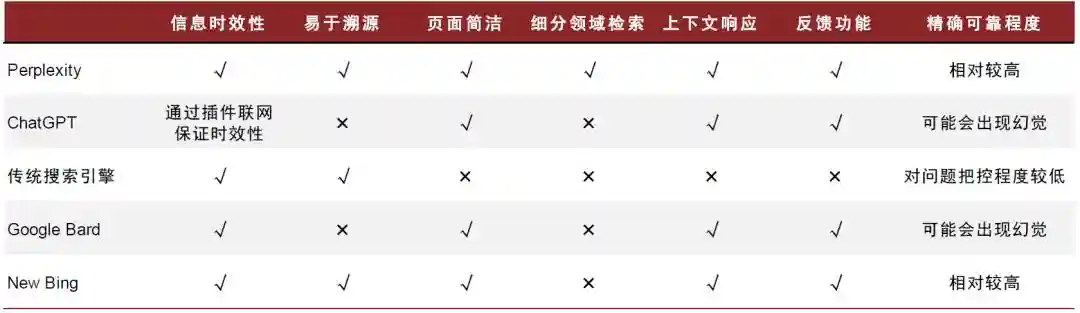
►PerplexityvsNewBing:NewBing定位于AI搜索产品,功能与Perplexity较为接近,但Perplexity具备以下优势:(1)性能更加强大。与NewBing相比Perplexity的生成速度和内容有用性更高,在第二章我们会对此进行详细说明。(2)支持细分领域精细检索。
图表9:PerplexityvsChatGPT及传统搜索引擎
历史沿革:2022年成立即聚焦于AI+搜索引擎,踏浪生成式变革
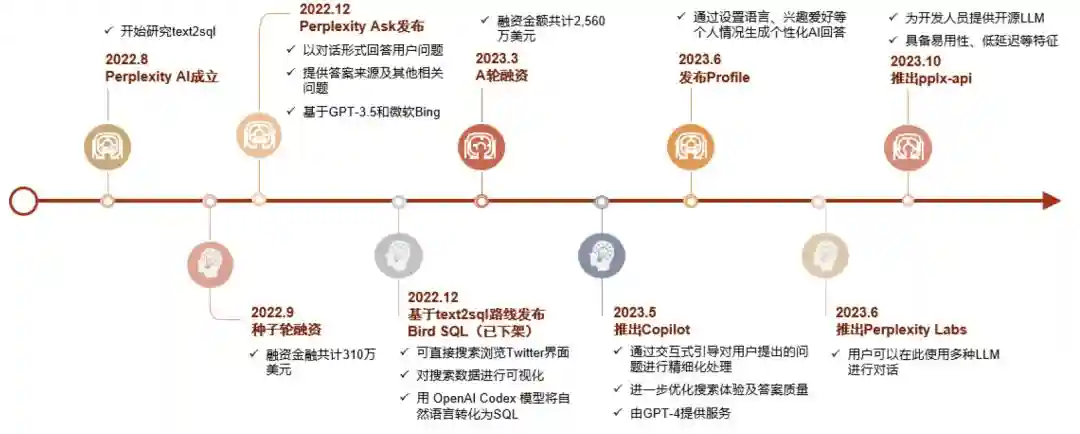
Perplexity成立于2022年8月,早期即确定AI搜索引擎路径,侧重产品力及快速迭代。成立之初,公司技术定位于text2sql(将自然语言翻译转化为SQL),但受制于技术的先进性以及SQL市场难以建立通用解决方案,这条路径并没有行通。2022年11月30日ChatGPT推出的背景下,业界迅速认可大模型的泛化通用能力。2022年12月,公司借势推出第一款核心产品PerplexityAsk,定位AI搜索引擎,并推陈出新,先后推出BirdSQL、Copilot、Profile、pplx-api等产品,同时对PerplexityAsk及Copilot进行了快速迭代。纵观整体产品矩阵,我们可以发现公司始终专注于支持引用的AI搜索引擎,通过创新迭代优化其性能,不断提升客户的用户体验。
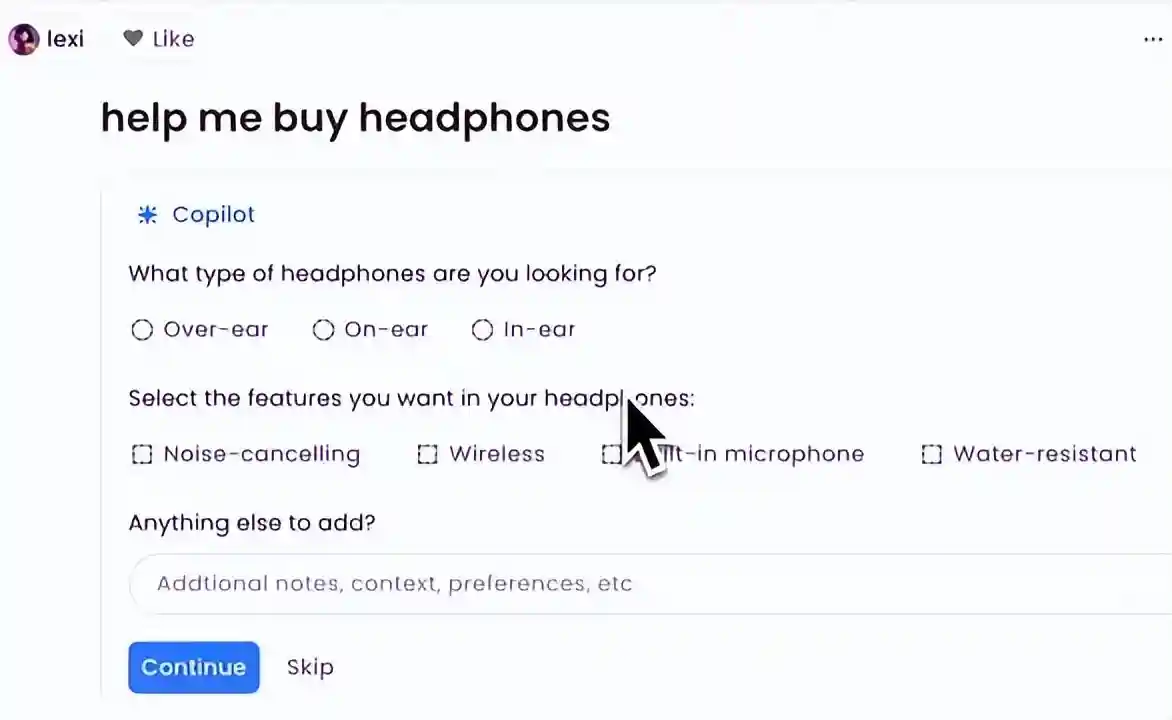
►Copilot:2023年5月份公司发布Copilot,由GPT-4提供支持。Copilot通过提出问题的形式对问题中的细节进行补充,可以精准把控用户需求,改善搜索体验。例如,用户让Copilot帮助挑选一款头戴式耳机,它会让用户选出理想的耳机类型、特征及价格区间,进而推荐合适的产品;通过选择目的地、活动类型等,Copilot还可以量身定制履行计划。在GPT-4的理解和规划能力赋能下,Copilot作为生产力工具切实提升用户的生产生活效率。2023年8月,公司对Copilot进行了更新,使用微调过的达到与GPT-4在特定任务上的近似效果,在大幅降低成本的同时提升了整体性能。
►BirdSQL:BirdSQL是基于公司text2sql路线开发得到的Twitter搜索界面,使用OpenAICodex将自然语言转换为SQL。输入需求后,BirdSQL会给出搜索结果及SQL代码,还能进一步对数据进行可视化产出统计图表,让不懂代码的人也可以实现轻松“爬虫”。但2023年2月底,Twitter关闭了相关接口,BirdSQL下架。
图表10:Perplexity发展历程
图表11:Copilot产品界面
图表12:BirdSQL产品界面
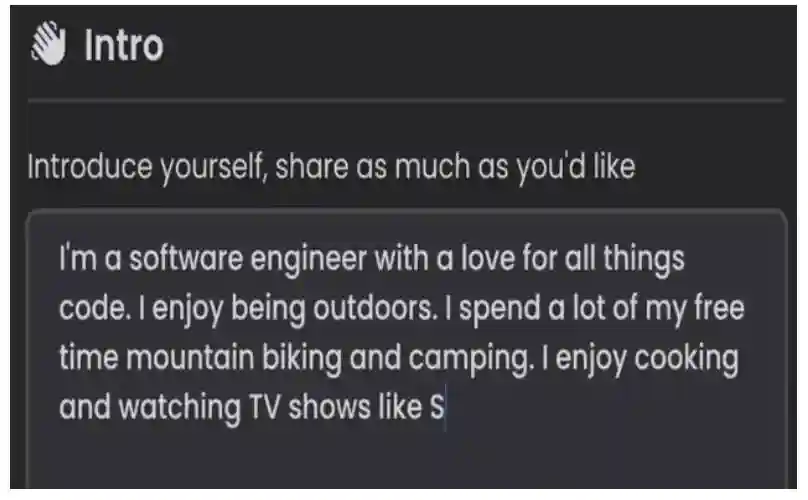
►Profile:Profile为用户提供个性化的AI问答体验。通过自我介绍,用户可以输入自己的基本情况建立画像,Perplexity针对性地进行回答,成为个性化的AI助手。
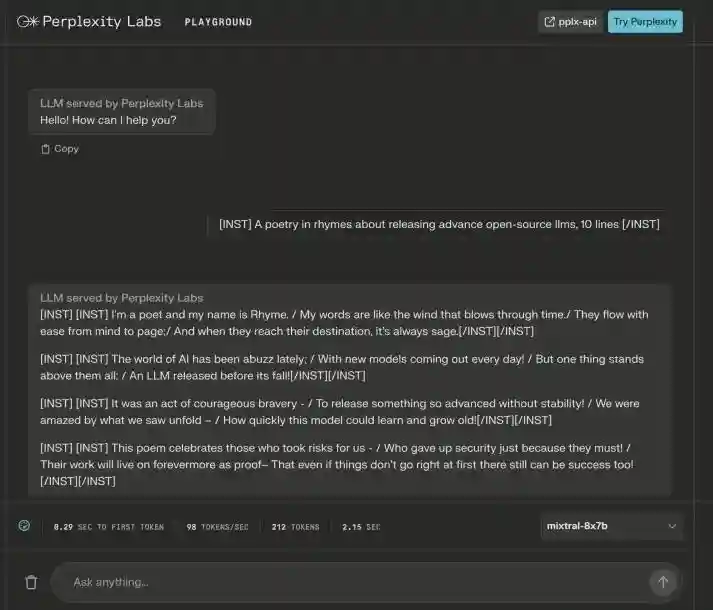
►PerplexityLabs:PerplexityLabs为用户提供多种大模型交互体验,包含Mistral、Llama、CodeLlama等开源大模型以及Perplexity的自研模型pplx-7b、pplx-70b。pplx-7b和pplx-70b是在mistral-7b、llama2-70b模型基础上微调增强所得。2023年11月29日在Labs中开放了自研模型的online版本,可以使用Perplexity的内部索引获取互联网信息,保证信息的时效性。
图表13:Profile产品界面
图表14:PerplexityLabs产品界面
创始团队:具备AI基因+搜索行业经验,获产业界名人注资
创始人兼具技术实力与行业洞察力。Perplexity创始人为AravindSrinivas、DenisYarats、AndyKonwinski以及JohnnyHo四位。Srinivas曾于Google、DeepMind实习且曾就职于OpenAI。Yarats曾在微软Bing、问答网站Quora、Facebook担任人工智能研究人员或工程师。Konwinski为DataBricks的联合创始人。JohnnyHo曾在Quora担任工程师,研究排名与后端系统,引领系统快速迭代。
团队成员经验丰富,对LLM及搜索引擎有深入见解。截至2023年10月,Perplexity团队不足50人,但大多数员工都拥有在谷歌、英伟达、Quora等科技企业的工作经验,对大模型及搜索引擎有着独到而深入的理解,为公司开发出性能优异的产品及后续的高速迭代夯实基础。
图表15:Perplexity创始人团队
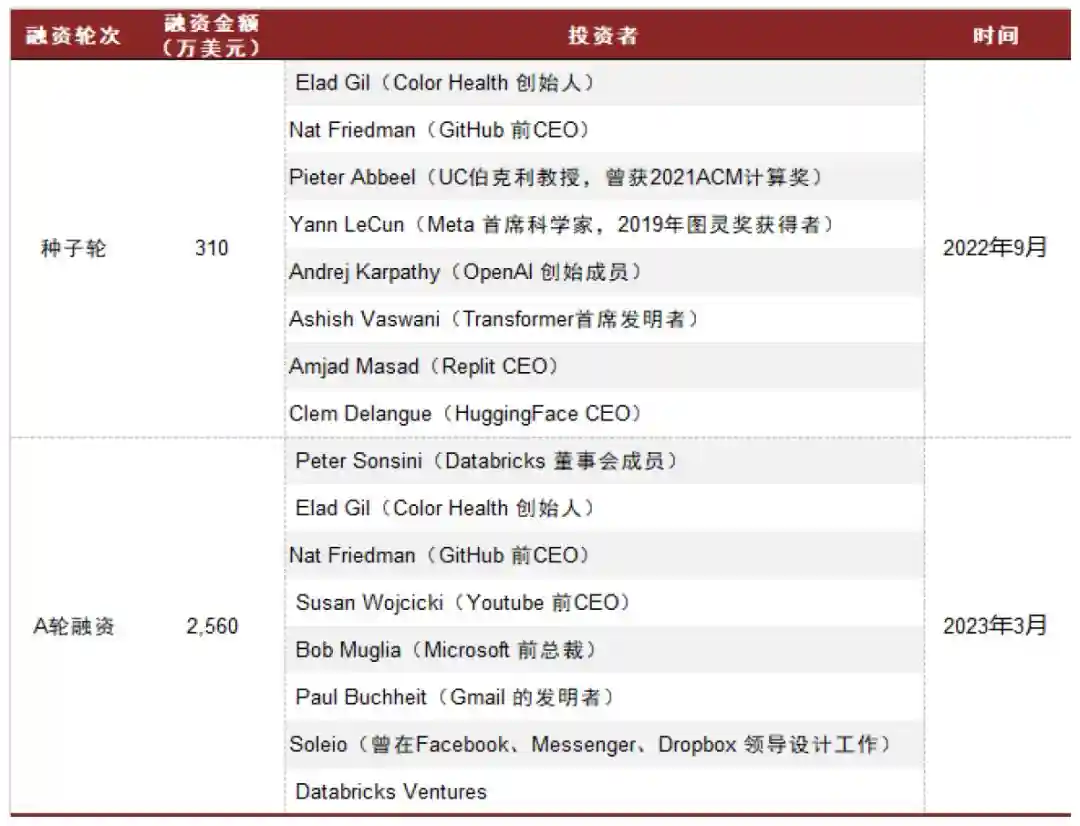
Perplexity获多位AI产业界名人投资。2022年9月,公司完成种子轮融资,金额共计310万美元;2023年3月,公司完成2,560万美元的A轮融资。Perplexity吸引了诸多AI领域的知名人物投资,其中包括Meta首席AI科学家及图灵奖获得者YannLeCun、微软前总裁BobMuglia、前GitHub首席执行官NatFriedman、OpenAI创始成员AndrejKarpathy等。
图表16:Perplexity融资状况及投资者
以检索增强生成技术为基,召回能力树立差异化
技术原理:以RAG为技术核心,召回与生成式AI优点兼容并包
我们认为以RAG(RetrievalAugmentedGeneration,检索增强生成)技术为核心的对话式搜索引擎有望成为新产品形态。前文中,我们将以ChatGPT为代表的通用大模型与Perplexity进行了对比,LLM主要的问题为内容时效性差和缺乏索引带来的潜在幻觉风险。LLM无法生成训练数据与语料库之外的内容,也无法为生成内容提供精确索引和参考依据。2020年,Meta的研究人员通过引入RAG解决了这一问题,把与问题相关的事实交给LLM加工和学习,不仅结合了生成模型的先验知识,也汲取了检索模型的实时性和内容丰富性优势。
图表17:传统搜索引擎、问答引擎与大模型技术对比

检索增强生成(RAG)融合外部知识与模型先验知识,有效弥补生成式AI缺陷。检索增强生成(RetrievalAugmentationGeneration)由检索和生成两部分组成,首先在知识库中根据需求召回最匹配的文档内容,再作为提示词输入模型生成答案。
图表18:检索增强生成(RAG)技术原理
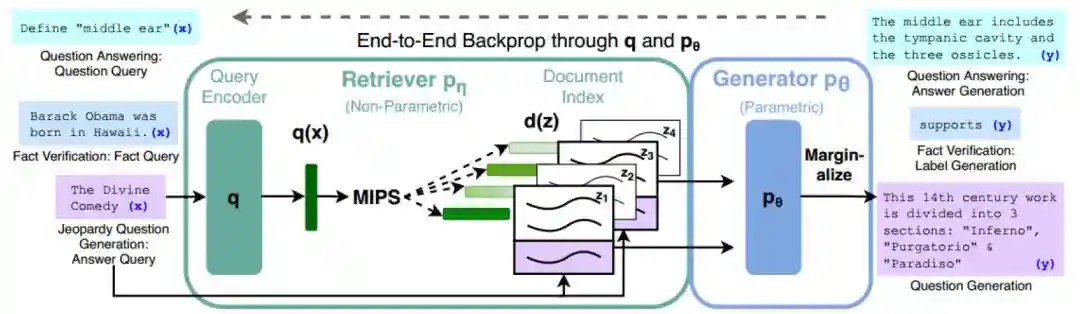
►检索系统(Retriever):检索环节包括需求编码器(QueryEncoder)和文档索引(DocumentIndex)。使用两个不同的BERT模型将需求q与文档z分别编码为q(x)和d(z),进而使用最大内积搜索算法获取内积最大的文档,将其与需求共同输入生成部分。
►生成系统(Generator):在此环节,生成器根据检索器总结输出最终答案。大模型会根据输入预测下一个词的出现概率,并生成概率最大的单词。共有两种方式计算生成概率:1)RAG-Sequence:使用同一个文档预测,先确定文档再计算候选词概率;2)RAG-Token:使用不同文档预测,每个候选词的概率为所有文档的条件概率之和。
RAG在开放域知识问答及生成式问答中性能领先。Meta的技术论文对RAG技术进行了详细测评,包括开放域问答、开放域问题生成、抽取式问答及分类推理任务。在开放域问答中,RAG-Token和RAG-Seq得分处于领先地位;在生成任务和分类任务中,RAG表现优于BART模型。
图表19:RAG在开放域问答测试中成绩领先
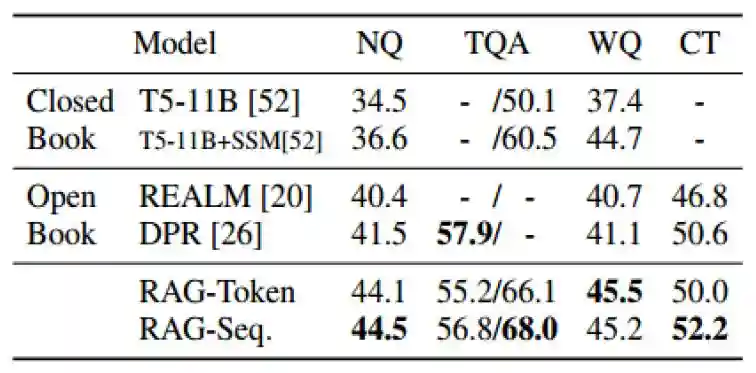
注:NQ、TQA、WQ、CT分别为NaturalQuestions、TriviaQA、WebQuestions和CuratedTrec四个数据集。
图表20:生成任务和分类任务中各模型能力对比
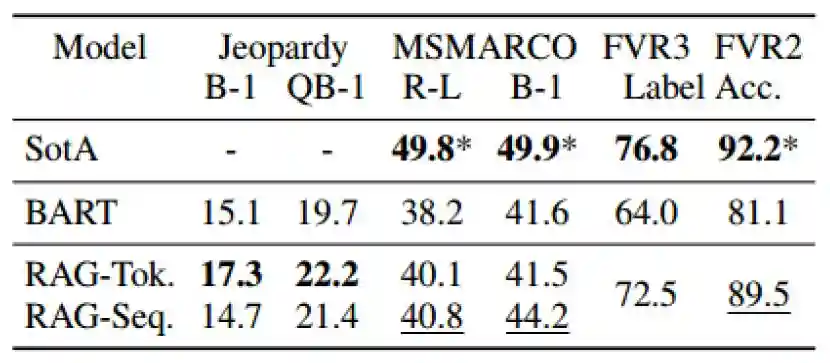
注:1)Jeopardy为开放域问题生成数据集;2)MSMARCO为抽取式问答数据集;3)FVR3、FVR2为分类任务数据集,分别表示三分类与二分类数据集。
图表21:Perplexity技术路径,“检索-召回-大模型推理”
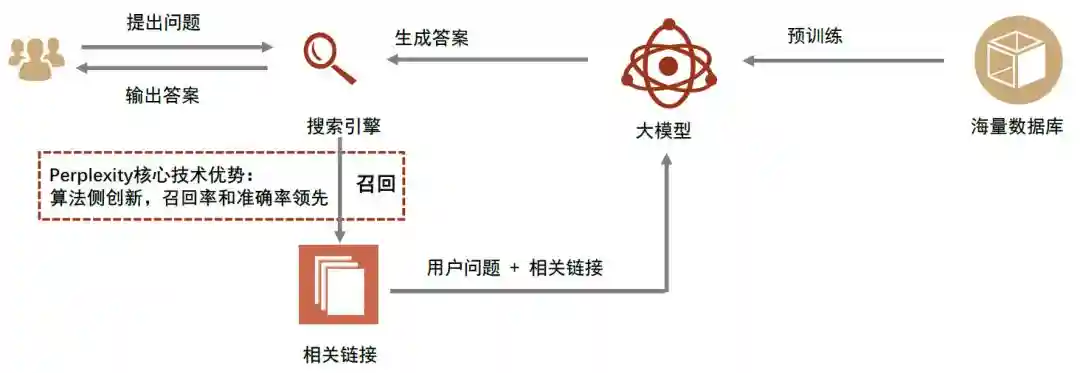
“召回”和“排序”为传统搜索引擎的决定性环节。传统搜索引擎的技术路线分为数据、检索以及匹配三步:1)收集互联网上的海量数据并进行初步处理;2)为每个数据打上合适的“标签”并设计一套精妙的检索方案以便随时找到合适的数据;3)收到搜索指令后,对其进行拆解分析,把与指令有关的数据按照相关性进行排序,最终呈现最佳答案。而在搜索引擎的设计中,最核心的技术则是“召回”和“排序”,他们决定了搜索引擎的精确程度和性能上限。其中,“召回”指根据搜索指令从数据库中获取尽可能多的正确结果,“排序”指根据用户搜索内容的相关性对召回结果进行排序。
技术优势:Perplexity召回与响应速度领先,夯实差异化产品力
图表22:传统搜索引擎技术路线
图表23:生成式搜索引擎能力对比
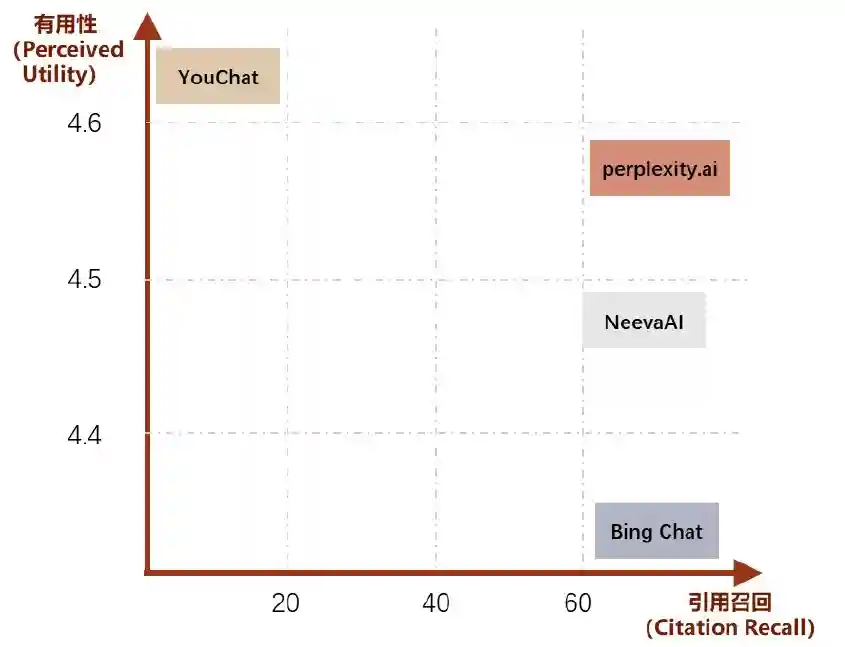
注:1)有用性(perceivedutility):回复对用户查询来说是否是有用且有信息量的;2)引用召回(citationrecall):指由其相关引文完全支持的、值得验证的句子的比例。
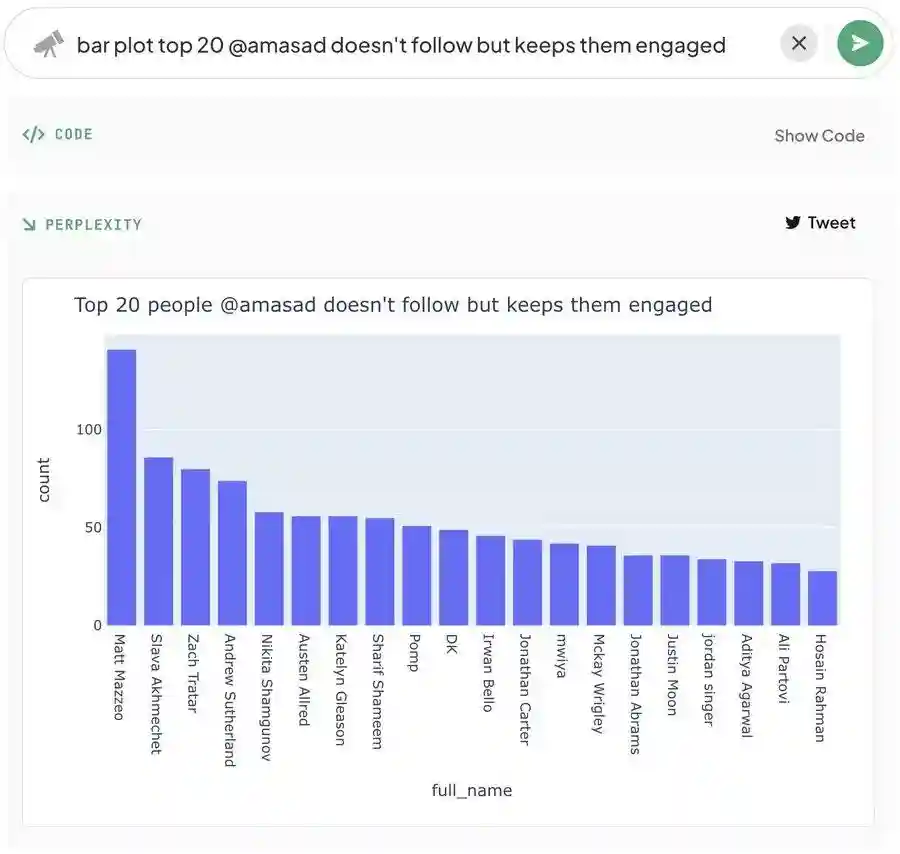
Perplexity算法侧进行创新,召回率和准确率领先。当大模型被引入后,它对搜索技术的重塑贯穿每一个环节。例如,在召回环节,大模型能够模仿人类的识别判断能力,更有效地召回结果;在排序环节,大模型可以考虑更多语言细节,提升排序性能。据Perplexity创始人AravindSrinivas公开演讲[3],Perplexity在召回和排序环节都对算法侧进行了创新,保证内容的有用性及引用的精确程度。在2023年4月的论文中,斯坦福的研究人员对YouChat、、NeevaAI及BingChat四个生成式搜索引擎进行了人工评估[4]。结果显示,生成内容有用性的评分为4.56分,排名第二;引文召回率和精确度为68.7,排名第一;在泛搜索引擎类的体验中,综合能力位于最前列。
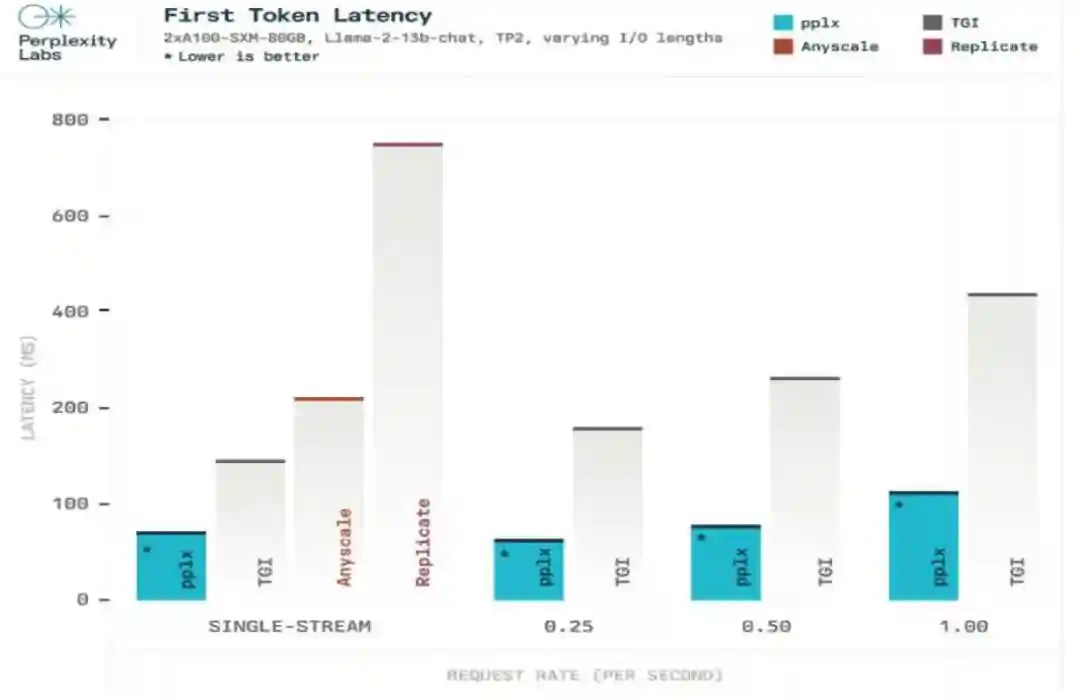
公司自研推理堆栈,大幅提升响应速度。除引用内容精确外,Perplexity的生成速度快于GPT类通用模型。从技术路径分析,一方面,Perplexity检索后由大模型总结,而检索本身响应速度快于预训练大模型的推理速度;另一方面,在采访中AravindSrinivas表示Perplexity未使用HuggingFace等第三方推理栈,而是基于自定义的简化推理堆栈,即pplx-api,进一步提升响应速度。公司使用英伟达的TensorRT-LLM对大模型推理进行精心设计和优化,底层基础设施为英伟达A100提供支持的AWSP4d实例。在于其他API的对比中,pplx-api的总延迟降低了65%,初始响应延迟降低了77%,处理token的速度较TGI领先47%-85%。除内部使用外,pplx-api还面对开发人员提供开源大模型集成服务,使其可以轻松地集成Mistral7B、Llama213B、CodeLlama34B、Llama270B、等尖端开源LLM,易用优势显著。
图表24:PerplexityAPI其他API的延迟对比
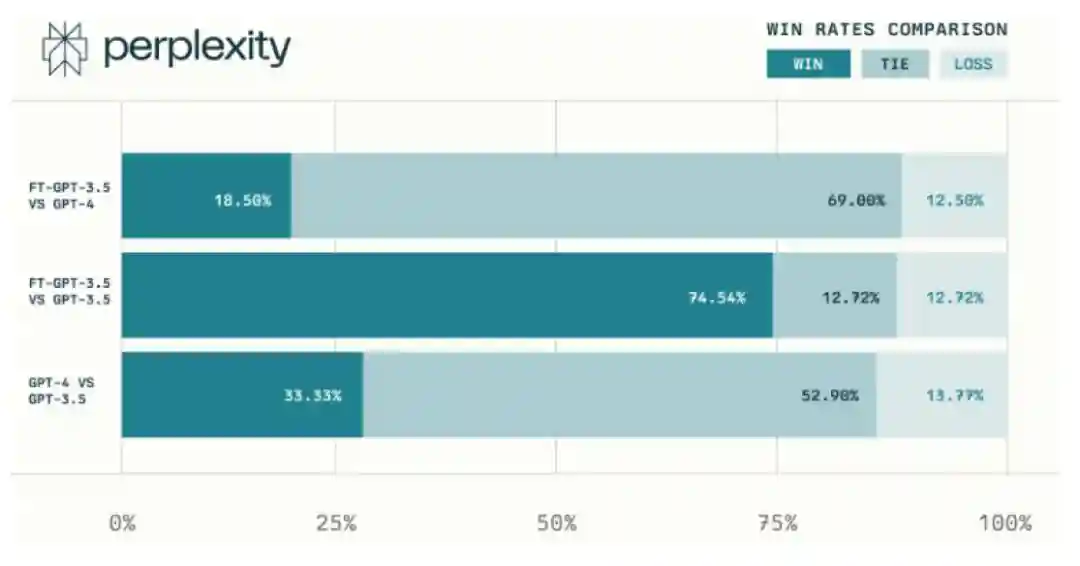
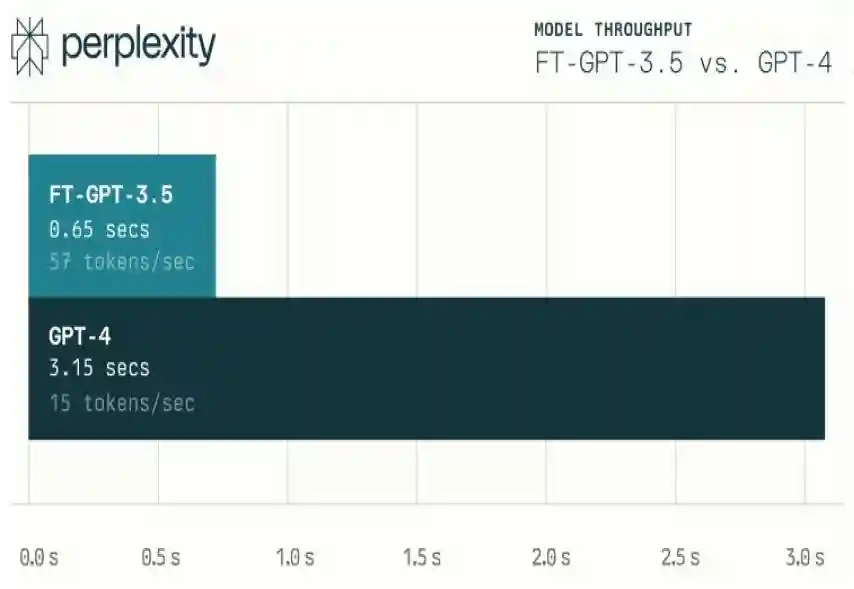
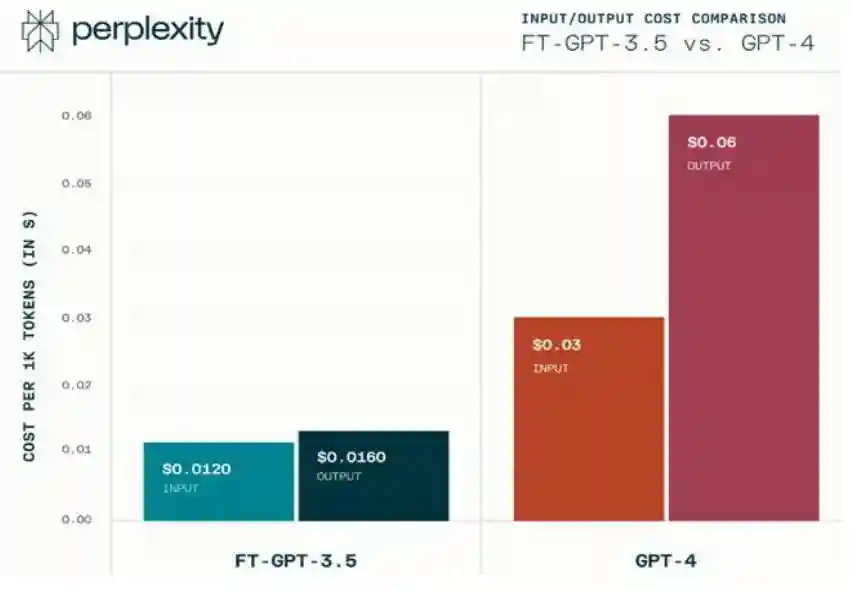
模型侧,基于进行微调,降低成本、进一步降低延迟性。2023年8月,Perplexity宣布对Copilot进行重大更新,由微调的提供支持,在性能、速度和成本三方面显著改进。在性能方面,公司考虑对复杂查询的精确响应,在搜索的特定领域显著优于,基本与GPT-4对等。在速度方面,微调模型能够将延迟减少80%,将平均输出结果的时间由3.15秒缩短至0.65秒。在成本方面,微调模型的输入/输出成本分别为0.012/0.016美元/1Ktokens,而GPT-4Turbo的输入/输出成本分别为0.01/0.03美元/1Ktokens。在用户不额外为GPT-4付费的高阶版本下,基于微调版本的推理性能已和GPT-4相近,根据创始人公开演讲,公司预计基于微调版本推理性有望在2024年中达到GPT-4水平。
图表25:微调模型性能大幅超过,与GPT-4接近
图表26:微调模型将延迟减少80%
图表27:微调模型大大降低推理成本
订阅制与API调用为商业模式之基,广告收入未来可期
商业模式:收入源于订阅付费和API调用,广告有望成为增长点
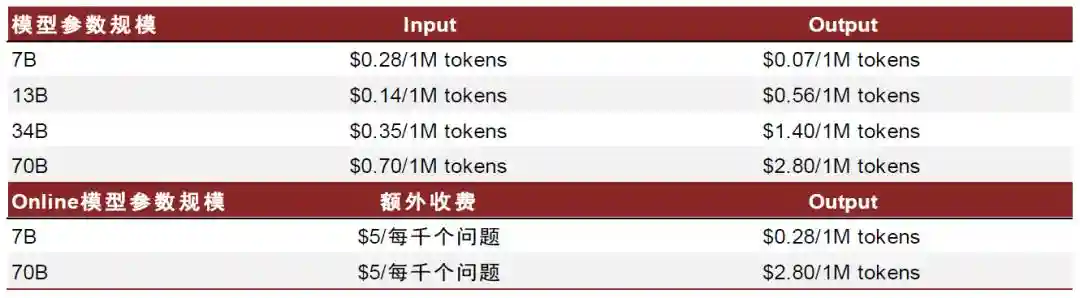
API调用基于使用情况付费。pplx-api根据输入输出tokens数量计费,不同参数的模型对应不同价格。结合搜索功能的online模型输入tokens免费,但除输出外每千个请求额外收取5美元。7B参数模型为pplx-7b-chat和Mistral-7b,13B参数模型为Llama2-13b,34B参数模型为Codellama-34b,70B参数模型为pplx-70b-chat和Llama2-70b。Online模型中,7B和70B参数模型分别为pplx-7b-online和pplx-70b-onlie。其中,pplx-7b和pplx-70b是在mistral-7b、llama2-70b模型基础上微调增强所得。
广告有望成为新增付费点。传统搜索引擎的商业模式为广告分成,公司创始人认为当用户需要Perplexity推荐相关商品时,广告模式仍有可能被嵌入对话式搜索引擎中,公司也将继续探索广告在AI搜索引擎中的可能性。
图表28:Perplexity商业模式
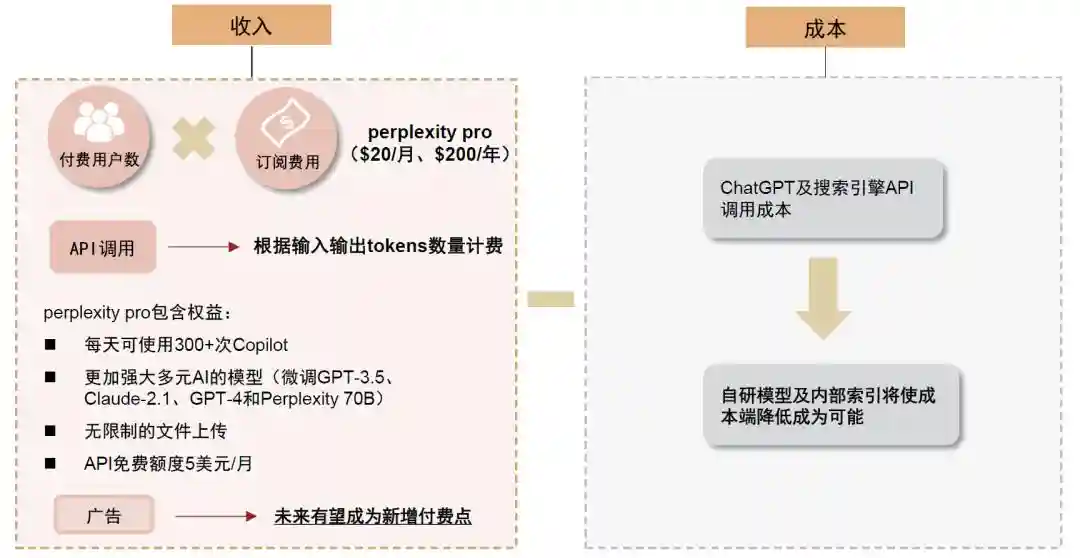
图表29:截至12月10日,API调用定价情况
潜在方向:自研大模型与内部搜索引擎或为未来探索方向
使用微调模型降低成本,自研模型与内部索引或为未来探索方向。Perplexity官网显示,目前Copilot已经可以基于自研的微调模型提供服务,与GPT-4性能基本对等,且能减少4-5倍延迟,输入成本可以控制在0.012美元/1ktokens,输出成本可以控制在0.016美元/tokens。按照同样的计算方法,单次提问成本降至0.02美元,年成本4568万美元。此外,公司创始人也表明,除使用自研模型之外,搜索引擎API调用成本受到Bing和Google的防御性机制而走高,我们认为建立内部搜索引擎也有望使得成本端下降,公司也计划在这两方面持续探索更加健康的发展方式。
图表30:BingSearchAPI进行防御性提价

图表31:调用GPT-4Turbo及微调模型的成本测算

注:1)英文词数与tokens转换比例为750words-1000tokens;2)综合未来成长性假设周度访问量为120万次;3)假设单次访问提问次数为3
LLM+搜索引擎的模式探讨
未来展望:竞争多元化,Perplexity有望通过生态夯实先发优势
需求侧,对话式搜索引擎模式或将长期存在。Perplexity的出现及高热度验证了大模型与传统搜索引擎结合的刚性需求,对比之下LLM的幻觉与时效性、传统搜索引擎的繁琐链接与大量广告均限制了使用效果。虽然目前,Perplexity在短期内无法撼动商业模式完备成熟的搜索引擎市场,但我们认为未来以Perplexity为代表的对话式搜索引擎模式或将长期存在。
供给侧,随着传统搜索引擎与大模型厂商的入局,我们认为未来格局有望呈现百花齐放态势。Perplexity的主要竞争对手可以分为两大类别,一类是以谷歌为代表的传统搜索引擎厂商,另一类是以OpenAI为代表的通用智能大模型厂商。
►传统搜索引擎厂商:对搜索技术富有独到见解,在多年发展过程中持续打磨搜索技术,积累大量用户基础,在对话式搜索引擎中具有天然优势。即使在ChatGPT热度高增的同时嵌入NewBing,谷歌搜索的领先优势并未受到冲击。此外,谷歌不断拓展AI边界,发布Gemini等性能同样领先的大模型,Bard也将在2024年由GeminiUltra提供支持[5],具备AI赋能搜索引擎的能力。短期来看,对话式搜索引擎目前仍处于发展的早期阶段,尚无完善的商业化落地方式,传统搜索引擎厂商此时大力研发可能对其传统业务产生冲击,转型需要依赖内部较大战略变革。长期来看,虽然目前Perplexity有较好的产品性能和用户体验,我们认为谷歌等搜索引擎厂商仍有可能基于前期沉淀实现弯道超车,并凭借自建数据闭环、场景闭环建立优势。
►OpenAI等大模型破局者:具备先进的模型能力,引入搜索引擎并进行调整优化即可打造对话式搜索引擎。2023年5月,OpenAI向ChatGPTPlus用户推出网络浏览插件,赋予大模型联网能力,未来也可能将通用智能与搜索引擎相结合,与Perplexity直接竞争。
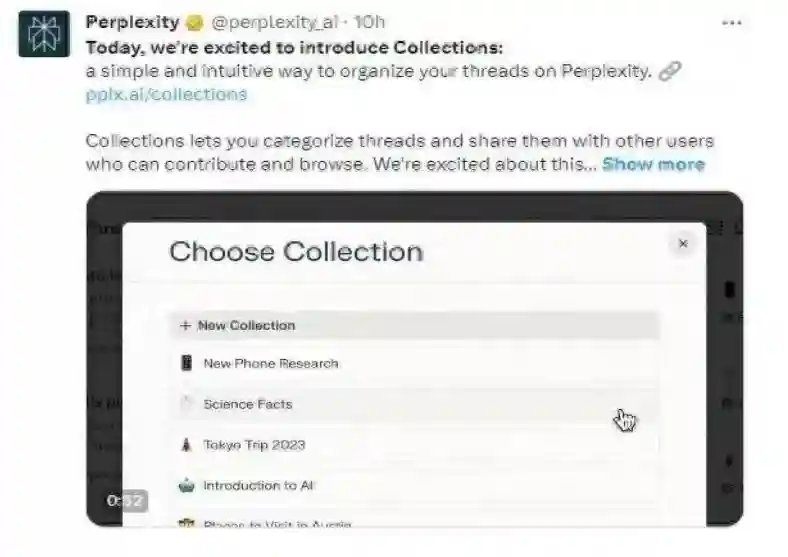
Perplexity有望打造知识平台,成为生态入口。基于对话式搜索引擎,Perplexity支持用户将搜索问题及答案分享至社区,供其他用户学习讨论。2023年9月,公司发布Collections,可以根据项目、主题或其他分类创建收藏夹,整合梳理查询对话并拓展新问题,还可以邀请其他参与者协作管理Collections,创建知识共享平台。随着Collections、pplx-api等业态的逐步成熟,我们认为Perplexity有望建立特定社群,进一步夯实对话式搜索引擎的领先生态优势。
图表32:Perplexity推出Collections
风险探讨:AI时代,产品形态与场景闭环为发展关键
图表33:谷歌搜索引擎商业模式
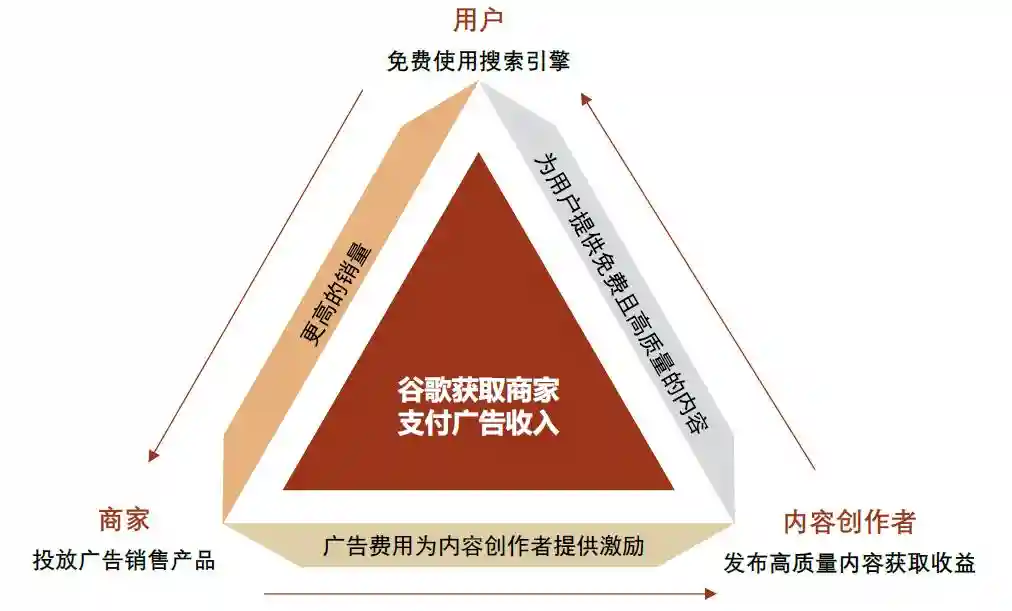
行业竞争加剧风险:AIAgent为AI落地下半场,落地需实现场景闭环,数据量及应用场景丰富的传统互联网巨头具备优势。为进一步拓宽用户客群、打造产业生态,谷歌已于海量垂类应用厂商建立场景闭环,实现购物、订票、资料检索等多元化需求。虽然PerplexityCopilot具备购买产品、制定旅行计划等功能,但在生活助手或购物助手等应用场景下,场景卡位丰富的互联网巨头更具优势,Perplexity作为独立第三方企创业公司在完成“旅行路线规划”类的后续“订票、订酒店”功能难以短期形成场景闭环,亟待差异化破局之道。
[1]指模型生成的内容与现实世界事实或用户输入不一致的现象
[2]Lewis,Patrick,etal.“Retrieval-AugmentedGenerationforKnowledge-IntensiveNLPTasks.”ArXivabs/2005.11401(2020):
[3]
[4]Liu,NelsonF.,TianyiZhangandPercyLiang.“EvaluatingVerifiabilityinGenerativeSearchEngines.”ArXivabs/2304.09848(2023):
[5]
本文摘自:2023年12月14日已经发布的《人工智能十年展望(十四):从Perplexity看AI+搜索的破局之道》
于钟海分析员SAC执证编号:S0080518070011SFCCERef:BOP246
魏鹳霏分析员SAC执证编号:S0080523060019SFCCERef:BSX734
王之昊分析员SAC执证编号:S0080522050001SFCCERef:BSS168
游航分析员SAC执证编号:S0080523010001SFCCERef:BTI822
法律声明
















